حملات سایبری میتواند با تاثیر بر تصاویر پزشکی، مدلهای تشخیص سرطان و متخصصان انسانی را فریب دهند
به گزارش مکاترونیک نیوز، مدلهای هوش مصنوعی (AI) تشخیص سرطان، که قادر به ارزیابی تصاویر پزشکی هستند، توان بالقوهای برای تسریع و افزایش دقت تشخیص سرطان را دارند، اما آنها می تواند در معرض حملات سایبری نیز قرار گیرند.
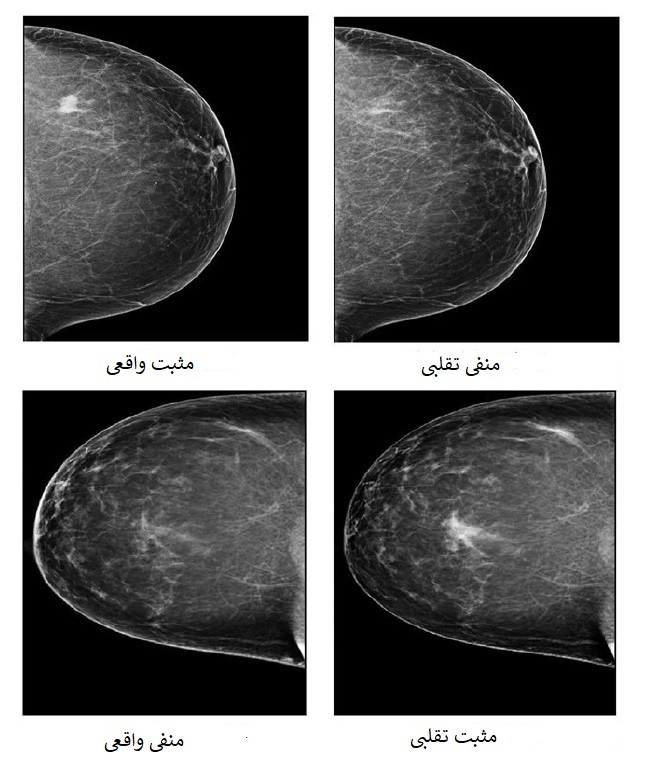
در یک مطالعه جدید، دانشمندان دانشگاه پیتسبورگ حملهای را تکرار کردند که در آن تصاویر ماموگرافی ساخته شد و مدل تشخیص سرطان سینه با هوش مصنوعی و همچنین متخصصان تصویربرداری رادیولوژی را فریب داد.
این مطالعه که اخیراً در مجلات نیچر منتشر شده است، توجه را به یک مورد ممکن جلب میکند
مشکل امنیت برای هوش مصنوعی پزشکی که به عنوان “حملات خصمانه” شناخته می شود، که به دنبال اصلاح تصاویر یا ورودیهای دیگر برای ساخت مدل هاب، رای رسیدن سیستم به نتایج نادرست است.
“آنچه می خواهیم با این مطالعه نشان دهیم، این است که این نوع حمله امکانپذیر است، و این حملات میتواند مدلهای هوش مصنوعی را به تشخیص اشتباه سوق دهد، که اشتباه پزشکی بسیار بزرگ است که می تواند امنیت و سلامت بیمار را با خطر مواجه کند. با درک اینکه مدلهای هوش مصنوعی در مواجهه با حملات خصمانه در زمینههای پزشکی چگونه رفتار میکنند، میتوان اندیشیدن در مورد راههایی جهت ایمنتر و قویتر کردن این مدلها را آغاز کرد.”
دکتر شاندونگ وو، نویسنده ارشد مطالعه و دانشیار رادیولوژی، انفورماتیک زیست پزشکی و مهندسی زیستی، دانشگاه پیتسبورگ
فناوری تشخیص تصویر مبتنی بر هوش مصنوعی برای تشخیص سرطان به سرعت در این کشور پیشرفت کرده است و در چند سال گذشته، چندین مدل سرطان سینه تاییدیه سازمان غذا و دارو ایالات متحده را به دست آوردند.
به گفته وو، این ابزارها میتوانند به سرعت تصاویر ماموگرافی را غربالگری کنند و مواردی که به احتمال زیاد سرطانی هستند را تشخیص دهند و به رادیولوژیستها کمک میکند که دقیقتر و کارآمدتر باشد. اما این فناوریها همچنین در معرض خطر تهدیدات سایبری مانند حملات خصمانه قرار دارند. انگیزههای احتمالی چنین حملاتی شامل تقلب بیمهای از سوی ارائهدهندگان مراقبتهای بهداشتی است که به دنبال افزایش درآمدند، یا شرکت هایی که سعی می کنند نتایج کارآزمایی بالینی را به نفع خود تغییر دهند.
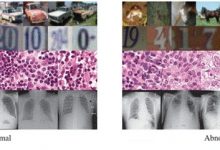
حملات خصمانه به تصاویر پزشکی از دستکاریهای دقیقهای که میتواند نتایج هوش مصنوعی را تغییر دهد، اما برای چشم انسان قابل تشخیص نیستند، تا نسخه های پیشرفتهتر که محتویات حساس تصویر، مانند نواحی سرطانی هدف قرار میدهند میباشند که احتمال فریب انسان را افزایش میدهند.
برای درک اینکه هوش مصنوعی چگونه تحت این نوع حملات خصمانه چندوجهی عمل می کند، دکتر وو و تیمش از تصاویر ماموگرافی برای ساختن مدلی برای شناسایی سرطان سینه استفاده کردند. ابتدا، دانشمندان یک الگوریتم یادگیری عمیق را برای افتراق سرطان و موارد خوش خیم با دقت بیش از 80٪ طراحی کردند.
سپس، آنها یک به اصطلاح “شبکه متخاصم مولد” (GAN) ایجاد کردند که یک برنامه ای کامپیوتر بود که با معرفی یا حذف مناطق سرطانی از تصاویر سرطانی منفی یا مثبت به ترتیب نتایج را تغییر میداد، سپس نحوه طبقهبندی مدل را برای این تصاویر خصمانه مورد بررسی قرار دادند.
از 44 تصویر مثبتی که توسط GAN منفی به نظر می رسید، 42 مورد به عنوان منفی توسط مدل، دسته بندی شدند و از 319 تصویر منفی که مثبت به نظر می رسیدند، 209 تصویر مثبت دسته بندی شدند. به طور کلی، مدل توسط 69.1٪ از موارد تصاویر نادرست فریب خورده است.
در بخش دوم آزمایش، دانشمندان از پنج رادیولوژیست انسانی خواستند تشخیص تقلبی یا واقعی بودن تصاویر ماموگرافی را تشخیص دهند. رادیولوژیست ها دقیقا اصالت تصاویر را با دقتی بین 29 تا 71 درصد بسته به فرد تشخیص دادند.
برخی از تصاویر جعلی که هوش مصنوعی را فریب میدهند ممکن است به راحتی توسط رادیولوژیست ها شناسایی شوند. با این حال، بسیاری از تصاویر متخاصم در این مطالعه نه تنها مدل را فریب دادند، بلکه آنها همچنین خوانندگان انسانی با تجربه را نیز فریب دادند. چنین حملاتی میتواند اگر منجر به تشخیص نادرست سرطان شود، به طور بالقوه برای بیماران بسیار مضر باشد
دکتر شاندونگ وو
دکتر شاندونگ وو، نویسنده ارشد مطالعه و دانشیار رادیولوژی، انفورماتیک زیست پزشکی و مهندسی زیستی، دانشگاه پیتسبورگ و همچنین مدیر آزمایشگاه محاسبات هوشمند برای تصویربرداری بالینی مرکز پیتسبورگ برای نوآوری هوش مصنوعی در تصویربرداری پزشکی است. به گفته وو، “گام بعدی ایجاد راه هایی برای تقویت مدل های هوش مصنوعی در مقابل حملات خصمانه است”
یکی از جهتهایی که ما در حال بررسی آن هستیم، «آموزش دشمن» برای مدل هوش مصنوعی است. این موضوع شامل پیش تولید تصاویر متخاصم و آموزش مدل است که این تصاویر چگونه دستکاری شده اند .
دکتر شاندونگ وو
وو افزود که با احتمال ادغام هوش مصنوعی در زیرساخت های پزشکی، آموزش امنیت سایبری نیز برای تضمین سیستم های فناوری بیمارستانی و پرسنل که از خطرات احتمالی آگاه هستند و راه حل های فنی برای محافظت از دادههای بیمار را دارند و همچنین امکان توقف نرم افزارهای مخرب ضروری است.
امیدواریم این تحقیق مردم را به فکر امنیت مدلهای هوش مصنوعی پزشکی بیاندازد و آنچه که میتوانیم برای دفاع در برابر حملات احتمالی انجام دهیم و از هوش مصنوعی اطمینان حاصل کنیم این است که سیستمها به طور ایمن برای بهبود مراقبت از بیمار کار کنند.
دکتر شاندونگ وو
منبع خبر : https://www.azorobotics.com
نام خبرنگار : مونا بنهری